https://www.youtube.com/watch?v=5jeVWOLW1bE
--> 잘 설명해놓은 유튜브 링크!
# Abstract

# Preliminaries
MAML (model-agnostic meta-learning algorithm)을 발전시킨 알고리즘. 한 개의 human demo만 봐도 따라가능.
1. domain shift btw provided data and evaluation setting
2. learn without labels (human's actions)
(1) Meta-learning: the ability to learn new tasks quickly and efficiently을 기르자.
여러 meta-training tasks로 학습하고 새로운 meta-test tasks로 검증하기.
meta-learning은 학습과 추론 모두 특정 p(T) 분포에서 sample 되는 task라고 가정한다.
optimize deep network's initial parameter setting = 대충 몇번의 gradient descent on a few datapoints 만으로도 충분히 effective generalization을 할 수 있게. (few-shot generalization)
learning a prior over functions and fine-tuning process as inference under the learned prior.
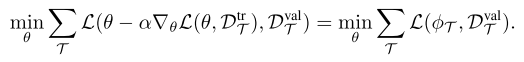
inner loss: adaptation objective, outer objective: meta-objective
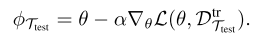
MAML은 one-shot imitation learning인데, teleoperation을 통해 모은 robot demo로 mean-squared error behavioral cloning을 수행했다. 하지만 이것은 raw video of human 이나 domain shift를 해결할 수 없기 때문에 이 논문에서는 그걸 해결할 예정.
#4 Learning from humans
A. Problem overview
사람 video로부터 배운다는 것은 inference problem이라 볼 수 있는데, 한번의 사람 데모만 보고 prior knowledge를 알아내서 robot policy parameter phi를 그 task에 맞게 추론하는 것.
사람 video 한번 보고 알려면 1. rich prior encapsulating visual and physical understanding of world, 2. 사람은 어느 종류의 결과를 선호하는지 3. 어떤 action이 로봇이 그것을 할 수 있게 하는지. 를 알고있어야한다.
--> pre-defined vision system, pre-determined set of human objectives, known dynamics model을 manual encoding 할수는 있지만 task-specific 하고 시간이 들고, data로부터 benefit을 얻지 못한다.


human은 observation만 제공, robot은 image, state, action을 제공한다. arm appearance, background clutter, camera viewpoint 변화가 있을 수 있는데, 아직 아무 가정도 하지 않음.
B. Domain-adaptive meta-learning
D_tr는 task T에 대해 하나의 사람 데모만을 가지고, D_val은 task T에 대해 여럿 robot demo를 가진다.
D_tr로 inner adaptation objective 계산할 때 human action을 몰라서 standard imitation learning loss를 못쓴다.
그래서 action이 필요없는 adaptation objective을 배우기로 했고, policy activation 때만 쓰기로 했다. 그렇게 하면서도 policy parameter를 업뎃하기 위한 gradient를 생산할 수 있고, gradient update 후엔 effective action을 생산할 수 있다.
meta-training에서 robot action을 가지고 supervise를 하기때문에 아예 불가능한 얘기가 아니다.
adaptation loss는 directing policy parameter update - policy가 제대로 된 visual cue를 보도록하여 제대로 된 action을 도출하도록 한다. --> psi가 adaptation objective

new task에 대해 policy parameter 추론할 때 1개의 human demo와 배운 loss L_psi로부터 theta를 위한 gradient descent를 이용한다.

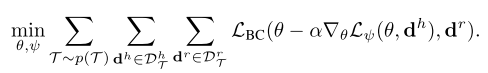
human policy가 phi인거고 psi가 로봇 policy 인듯!


C. Learned Temporal Adaptation objectives
human video에서 관련 정보들(의도, task-relevant objects)을 빼오는게 adaptation objective이다.
adaptation objective는 true action에 대한 정보 없이도 괜찮은 gradient info를 policy에 제공해야한다는 점에서 어렵다.
learned loss는 policy에 perceptual component를 바꿔서 맞는 object에 집중하도록 gradient를 제공한다. 그런데 어떤 behavior를 따라해야하고, 어떤 object가 관련있는지알기 위해서는 몇개의 frame을 봐야한다.
--> 이런 temporal information을 얻기위해 learned adaptation objective는 multiple time steps를 couple하고 multiple time step동안의 policy activation을 활용한다.

temporal convolution이 temporal, sequential data에 효율적이므로 adaptation objective L_psi는 multiple layers of 1D convolutions over time - 이게 traditional recurrent NN like LSTM보다 parameter efficient하고 더 간단하다.
MAML에서는 two-head architecture를 썼었는데, one head는 pre-update demonstration을 위해 쓰였고 the other은 post-update policy를 위한 것이었다. 이거는 특정 timestep에서 policy network의 마지막 hidden layer에 작용하는 learned linear loss function으로도 해석될 수 있다. loss and the gradient는 demo에서 모든 timestep을 평균내는 방식으로 계산되고. 이런 simple averaging은 temporal info를 담기에 효과적이지 않을 것이라서 다른 방식으로 temporal loss를 구했고 그건 single-timestep linear loss보다 좋다.
D. probabilistic interpretation
learned adaptation objective와 meta-learning을 한다는 것은 framework of probabilistic graphical model을 활용한다는 것과 같다. MAML도 approximately inferring a posterior over policy parameters phi given the evidence D_tr = d_h and a prior over the parameters given by theta.
phi = theta에서 시작해서 likelihood (1)에 gradient descent를 주는것은 MAP(maximum a posteriori) inference를 (2)에 주는 것과 같다. (theta는 weights에 Gaussian prior를 주는데 평균 theta이고 covariance는 step size와 gradient step의 개수에 의존적이다.)
log p(D^{tr}_T | \phi) ---(1)
log p(\phi | D^{tr}_T, \theta) ---(2)adaptation 은 learned loss인 L_psi (phi, D_tr)에 대해 gradient descent 하는거지, likelihood (1)에 하는게 아니다. 그리고 Gaussian prior log p(phi | theta)를 사용하기에 아래와 같은 joint distribution에 MAP inference를 하는것.
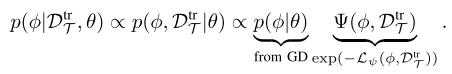
Bayesian inference는 phi를 통합하는게 필요하지만, MAP inference는 tractable alternative를 제공한다.
'논문리뷰' 카테고리의 다른 글
| Variational Imitation Learning with Diverse-quality Demonstrations 리뷰 (0) | 2021.08.12 |
|---|---|
| Handling Class Imbalance by Introducing Sample Weighting in the Loss Function (0) | 2021.08.02 |
| Inverse dynamics 설명( Wikipedia 210719) (0) | 2021.07.19 |
| Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization (0) | 2021.07.08 |
| Recent Advances in imitation learning from observation (0) | 2020.11.08 |