imitation learning 특성 상 optimal expert demonstration에 대해 imitation을 하는 경우가 대부분이었는데, 이와 다르게 diverse-quality demo가 주어졌을 때를 다룬 논문이다. 대부분 demonstration의 quality를 사전에 알고 있거나 알려주는 expert (confidence score, ranking score)가 등장하지만, 여기서는 quality와 reward를 variational approach로 활용하는 법을 논의한다.
이 논문에서는 diversity를 noise-densities로 측정함에 따라 quality가 확률 그래프로 나타나게 된다. 또한 그냥 quality-estimation을 하면 에러가 누적될 수 있으므로 reward를 활용하여 expert's decision making의 의도를 부여하고자 하였고, importance sampling을 활용하여 데이터 활용도를 높였다.
RL은 현실 세계에서 접하기 힘든 reward를 기반으로 한 알고리즘이라는 한계가 있고, imitation learning은 high-quality demo가 있어야만 제대로된 작동이 가능하다는 단점이 있다.
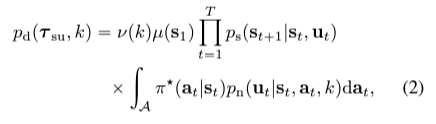
noise density p_n은 expert의 성능 비교도 하고, demo quality 비교도 할 수 있게함.
multi-modal policy는 different modality가 different policy를 측정한다. 근데 그건 여러 다른 expert들의 optimal policy를 측정하는 거라 quality가 다른 setting에서는 맞지 않는다. good modality를 찾기 위해서는 demo quality를 알아야하므로 세팅과 맞지 않다.

지도학습에서 diverse-quality data를 다루는 법은 quality를 측정하는 건데, parameterized model p_{theta, w}를 이용해 p_d를 측정할 수 있다. 하지만 이 방법은 에러가 누적되는 것에 취약하고, regression은 train과 test 때의 data distribution이 같다는 것을 가정하는데, data distribution은 policy에 의존적이므로 imitation learning에서 train/ test distribution은 다를 수밖에 없다.
# VILD: A robust method for diverse-quality demonstrations
(1) 먼저, noise-density와 reward function을 explicit하게 parameterized model 한다.
(2) 그리고 variational approach로 그 parameter를 추측하고,
(3) RL을 활용하여 구현하고,
(4) importance sampling으로 data-efficiency를 높였다.
------------------------------------------------------------------------------------------
(1) IRL로 reward를 구한다음에 RL로 policy를 찾으면 compounding error를 피할 수 있다. RL로 배우는 policy가 data distribution과 policy의 의존성을 고려하기 때문이다. (?) 따라서 이 논문은 maximum entropy IRL을 기반으로 p_d를 estimate하는데,
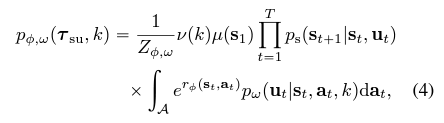
phi는 cumulative reward 가 joint probability density of actions given optimal policy에 비례하도록 한다.
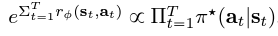
즉 optimal policy일 때 누적 reward가 커지는 것이다.

KL(A||B) = ∑ A log(A/B)
min KL(p_d || p_phi,w) = min ∑ p_d (log Z+ log(∫pi* p_n / ∫e^r p_w) )
=max (E_pd [ ∑ log (∫e^l )] - log Z)
(하... 열심히 썼는데 윈도우 업데이트가 다 날렸다... 임시저장도 안되었나...)
(2) variational approach는 Jensen inequality와 variational distribution으로 integral에 lower-bound를 줄 수 있다는 것인데.. integral은 optimal variational distribution의 expectation으로 최적화가 가능해서 선호하고 그렇게 접근했지만, optimal variational distribution 구하는 것도 sub-optimal problem이라 어려웠다.

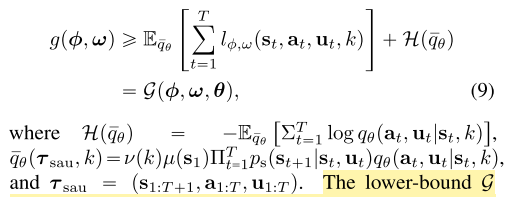
어쨌든 결론은 F-G 를 위와 같이 특정 variational model q_psi와 q_theta를 이용하여 lower-bound를 줄 수 있다는 것이고, 그 lower-bound는 maximum entropy RL과 유사하게 해결할 수 있다는 것이다. 그럼으로써 F-G 최적화를 할 수 있다.
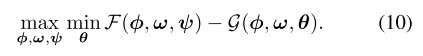
(3) RL로 density model 고르기.
(10)식을 최적화하기 위해서 아래와 같이 Gaussian distribution N으로 density model들을 꾸밀 수 있다. Covariance C가 클수록 low-expertise demo이고 작을수록 high-expertise라고 볼 수 있다.
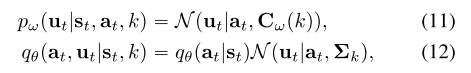
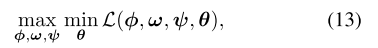
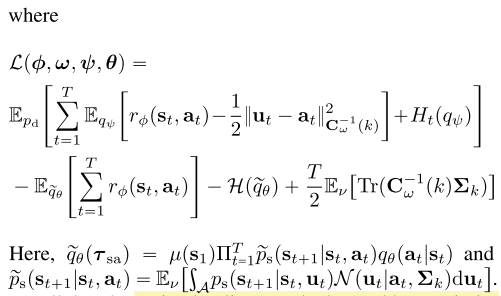
저렇게 density 모델을 잡고 최적화를 하면 (13) 식으로 나타낼 수 있고, minimize L w.r.t. theta는 transition probability tilda(p_s)와 reward r_phi에 대해 maximum entropy를 푸는것과 같기 때문에 RL로 풀 수 있다.